Publications
2024:
A. Roy, R. Moulick, V. K. Verma, S. Ghosh, A. Das; Computer Vision and Pattern Recognition (CVPR), 2024
[Project] [Code] [Poster]
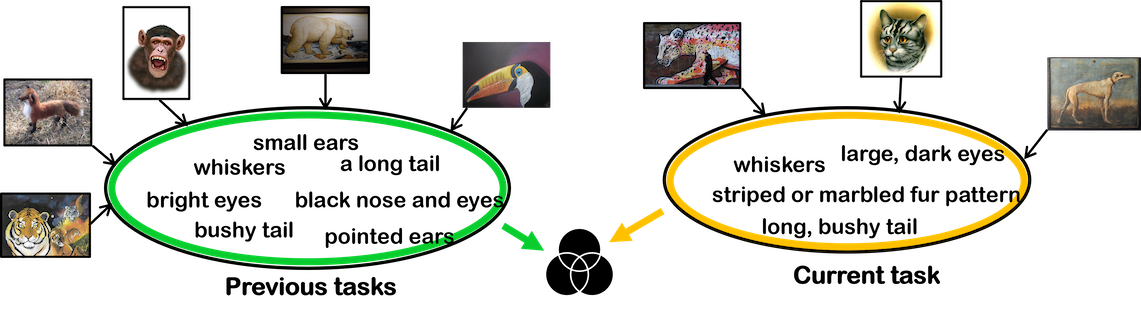 In this work, we leverage on prompt learning to address catastrophic forgetting in a continual learning scenario. unlike existing approaches, we don't rely on a pool of prompts to learn from. Instead, we employ convolution to create prompts that uses embeddings shared across layers enabling both layer-specific learning and better concept transfer across tasks. The intelligent use of convolution enables us to maintain a low parameter overhead without compromising performance. We further leverage Large Language Models to generate fine-grained text descriptions of each category which are used to get task similarity and dynamically decide the number of prompts to be learned.
In this work, we leverage on prompt learning to address catastrophic forgetting in a continual learning scenario. unlike existing approaches, we don't rely on a pool of prompts to learn from. Instead, we employ convolution to create prompts that uses embeddings shared across layers enabling both layer-specific learning and better concept transfer across tasks. The intelligent use of convolution enables us to maintain a low parameter overhead without compromising performance. We further leverage Large Language Models to generate fine-grained text descriptions of each category which are used to get task similarity and dynamically decide the number of prompts to be learned. |
(Best Paper Honorable Mention - Research Track)
S. K. Perepu, K. Dey, A. Das; ACM Joint International Conference on Data Science & Management of Data (CODS-COMAD), 2024
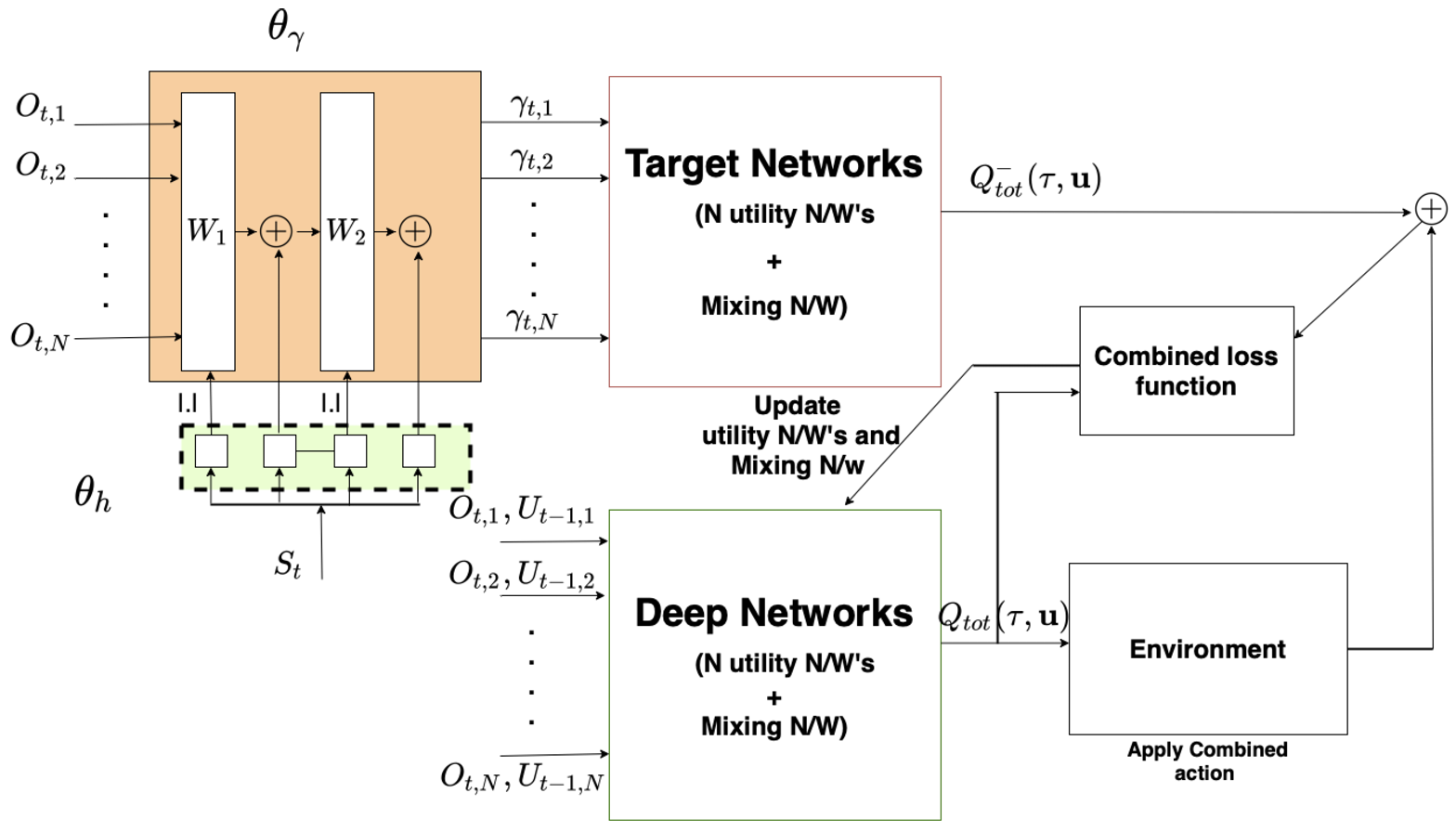 In this work, we address a multi agent reinforcement learning scenario when some of the agents degrade and perform noisy actions. In such a case, the good agents have to undertake the responsibility of more complex tasks while leaving the simpler tasks of shorter trajectory to noisy agents. The proposed method, Deep Stochastic Discount Factor (DSDF), based on the degree of degradation, tunes the discount factor for each agent uniquely, thereby altering the global planning of the agents. Moreover, our method allows to address changing degree of degradation of the agents without extensive retraining. Results on benchmark environments show the efficacy of the approach compared to the existing ones.
In this work, we address a multi agent reinforcement learning scenario when some of the agents degrade and perform noisy actions. In such a case, the good agents have to undertake the responsibility of more complex tasks while leaving the simpler tasks of shorter trajectory to noisy agents. The proposed method, Deep Stochastic Discount Factor (DSDF), based on the degree of degradation, tunes the discount factor for each agent uniquely, thereby altering the global planning of the agents. Moreover, our method allows to address changing degree of degradation of the agents without extensive retraining. Results on benchmark environments show the efficacy of the approach compared to the existing ones. |
A. Roy, V. K. Verma, S. Voonna, K. Ghosh, S. Ghosh, A. Das; International Conference on Computer Vision (ICCV), 2023
[Project] [Code]
 Existing continual learning approaches have mostly focused on convolutional neural networks. In this paper, we introduce a convolution based reweighting of the key, query, and value weights of the multi-head self-attention layers of a transformer for class/task incremental learning which does not require task-id to be explicitly present during inference and avoids the need for storing previous training instances. The convolution based reweighting enables us to maintain low parameter requirements per task. Experiments on four benchmark datasets demonstrate the superiority of the propsoed approach.
Existing continual learning approaches have mostly focused on convolutional neural networks. In this paper, we introduce a convolution based reweighting of the key, query, and value weights of the multi-head self-attention layers of a transformer for class/task incremental learning which does not require task-id to be explicitly present during inference and avoids the need for storing previous training instances. The convolution based reweighting enables us to maintain low parameter requirements per task. Experiments on four benchmark datasets demonstrate the superiority of the propsoed approach. |
O. Chakraborty, A. Sahoo, R. Panda, A. Das; International Conference on Learning Representations (ICLR), 2023
[Project] [Code]
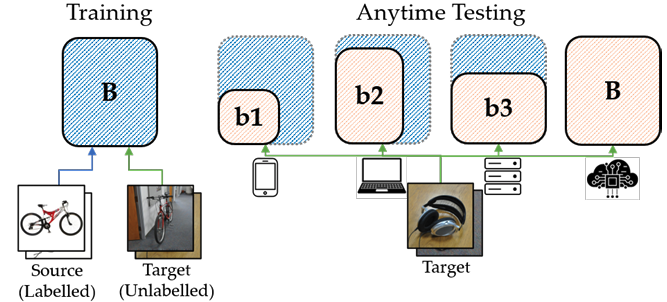 Existing unsupervised domain adaptation approaches are constrained to testing under a specific target setting, limiting their impact for many real-world applications. In this paper, we introduce a simple yet effective framework for anytime domain adaptation that is executable with dynamic resource constraints to achieve accuracy-efficiency trade-offs under domain-shifts. We achieve this by training a single shared network using both labeled source and unlabeled data, with switchable depth, width and input resolutions on the fly to enable testing under a wide range of computation budgets.
Existing unsupervised domain adaptation approaches are constrained to testing under a specific target setting, limiting their impact for many real-world applications. In this paper, we introduce a simple yet effective framework for anytime domain adaptation that is executable with dynamic resource constraints to achieve accuracy-efficiency trade-offs under domain-shifts. We achieve this by training a single shared network using both labeled source and unlabeled data, with switchable depth, width and input resolutions on the fly to enable testing under a wide range of computation budgets. |
K. Dey, S. K. Perepu, P. Dasgupta, A. Das; IEEE NetSoft, 2023
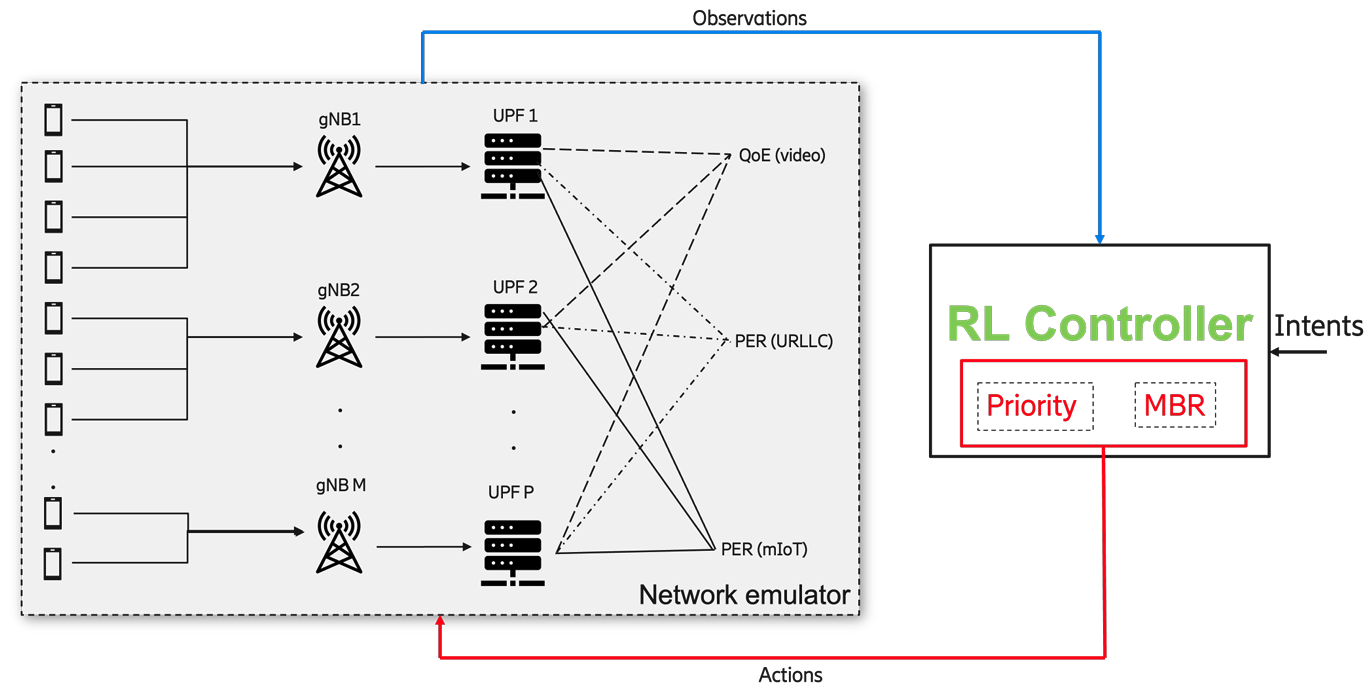 The dynamic and evolutionary nature of service requirements in wireless networks has motivated the telecom industry to consider intelligent self-adapting Reinforcement Learning (RL) agents for controlling the growing portfolio of network services. However, an RL agent trained for managing the needs of a specific service type may not be ideal for managing a different service type without domain adaptation. We provide a simple heuristic for evaluating a measure of proximity between a new service and existing services, and show that the RL agent of the most proximal service rapidly adapts to the new service type through a well defined process of domain adaptation.
The dynamic and evolutionary nature of service requirements in wireless networks has motivated the telecom industry to consider intelligent self-adapting Reinforcement Learning (RL) agents for controlling the growing portfolio of network services. However, an RL agent trained for managing the needs of a specific service type may not be ideal for managing a different service type without domain adaptation. We provide a simple heuristic for evaluating a measure of proximity between a new service and existing services, and show that the RL agent of the most proximal service rapidly adapts to the new service type through a well defined process of domain adaptation. |
A. Sahoo, R. Panda, R. Feris, K. Saenko, A. Das; Winter Conference on Applications of Computer Vision, 2023.
[Project] [Code] [Poster] [Video presentation] [Slides]
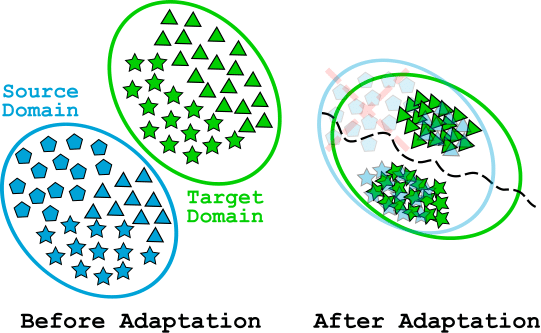 We develop a novel 'Select, Label, and Mix' (SLM) framework to address 'Partial Domain Adaptation' (PDA) problem that assumes target domain data are not only unlabeled but also some classes may not contain any data. SLM aims to learn discriminative invariant feature representations by first selecting relevant data from the source domain for adaptation and then imparting discriminitiveness by pseudolabeling and different types of mixup operation. Extensive experiments on several benchmark datasets demonstrate the superiority of our proposed framework over state-of-the-art methods.
We develop a novel 'Select, Label, and Mix' (SLM) framework to address 'Partial Domain Adaptation' (PDA) problem that assumes target domain data are not only unlabeled but also some classes may not contain any data. SLM aims to learn discriminative invariant feature representations by first selecting relevant data from the source domain for adaptation and then imparting discriminitiveness by pseudolabeling and different types of mixup operation. Extensive experiments on several benchmark datasets demonstrate the superiority of our proposed framework over state-of-the-art methods. |
A. Sahoo, R. Shah, R. Panda, K. Saenko, A. Das; Neural Information Processing Systems, 2021.
[Project] [Code]
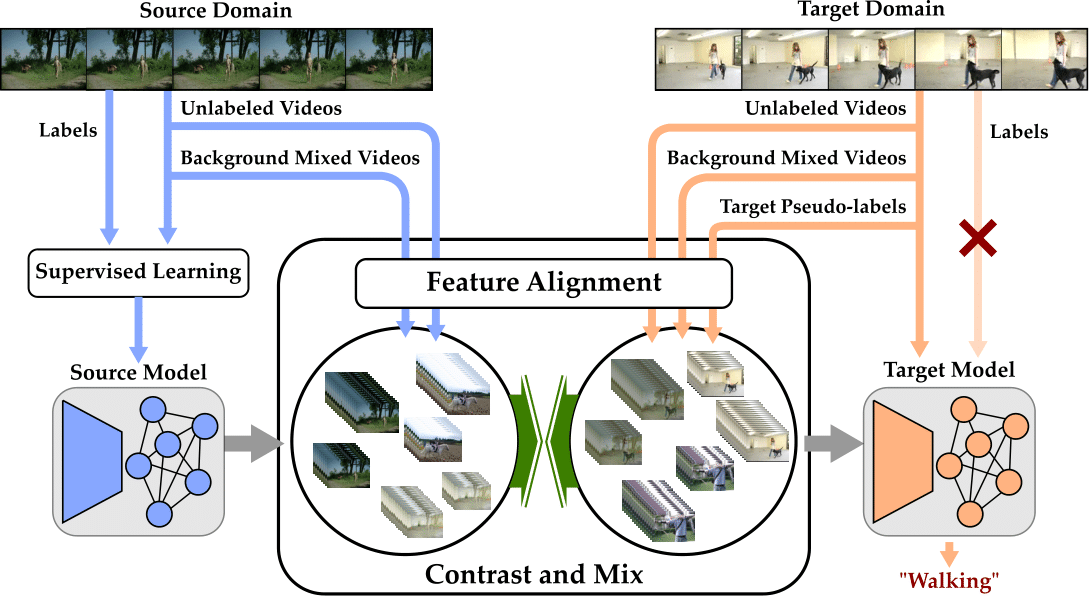 In this paper we addressed unsupervised domain adaptation problem in videos where we have labeled videos from a source domain but unlabeled videos in a target domain with different distribution of videos compared to the source. Contrastive learning by maximizing the similarity between videos at two different speeds as well as minimizing the similarity between different videos played at different speeds helps in good representation learning. In addition, extending such temporal contrastive learning by mixing background from videos in other domain helps in reducing the domain gap without any explicit domain adaptor. We also leverage on pseudo-labels from the unlabeled target domain videos to contrast between groups of similar videos. Extensive experiments on several benchmark datasets demonstrate the superiority of our proposed approach over state-of-the-art methods.
In this paper we addressed unsupervised domain adaptation problem in videos where we have labeled videos from a source domain but unlabeled videos in a target domain with different distribution of videos compared to the source. Contrastive learning by maximizing the similarity between videos at two different speeds as well as minimizing the similarity between different videos played at different speeds helps in good representation learning. In addition, extending such temporal contrastive learning by mixing background from videos in other domain helps in reducing the domain gap without any explicit domain adaptor. We also leverage on pseudo-labels from the unlabeled target domain videos to contrast between groups of similar videos. Extensive experiments on several benchmark datasets demonstrate the superiority of our proposed approach over state-of-the-art methods. |
A. Singh, O. Chakraborty, A. Varshney, R. Panda, R. Feris, K. Saenko, A. Das; Computer Vision and Pattern Recognition (CVPR), 2021.
[Project] [Code] [Poster] [video presentation]
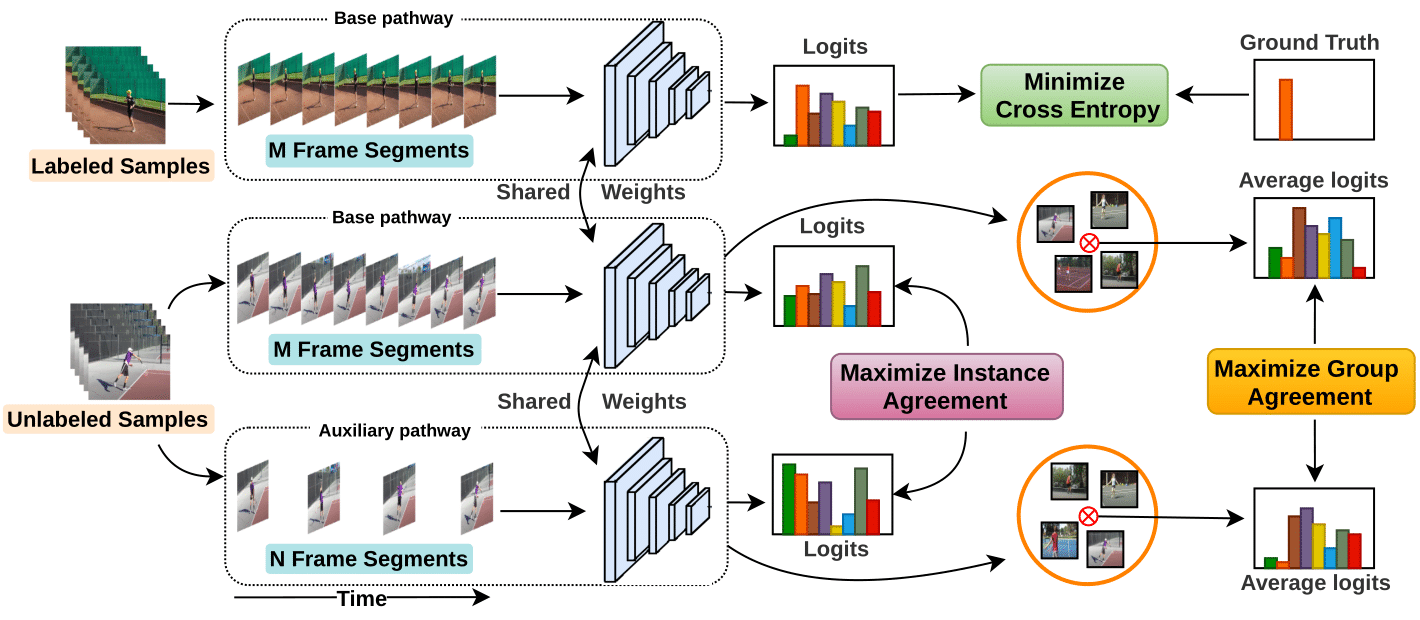 Success of Deep Learning models is critically dependent on training with large datasets requiring tedious human annotation. Annotating videos is particularly difficult as they need to be watched till the end. Starting with only a handful of labeled videos, we address the semi-supervised video action recognition problem by leveraging on the rich supervisory information: 'time' that is present in otherwise unlabeled pool of videos. We propose to learn a two-pathway Temporal Contrastive Learning (TCL) model where the similarity between representations of the same video at two different speeds are maximized while the similarity between different videos played at different speeds are minimized. With this simple yet effective strategy of manipulating video playbackrates, we considerably outperform video extensions of sophisticated state-of-the-art semi-supervised image recognition methods across multiple diverse benchmark datasets and network architectures.
Success of Deep Learning models is critically dependent on training with large datasets requiring tedious human annotation. Annotating videos is particularly difficult as they need to be watched till the end. Starting with only a handful of labeled videos, we address the semi-supervised video action recognition problem by leveraging on the rich supervisory information: 'time' that is present in otherwise unlabeled pool of videos. We propose to learn a two-pathway Temporal Contrastive Learning (TCL) model where the similarity between representations of the same video at two different speeds are maximized while the similarity between different videos played at different speeds are minimized. With this simple yet effective strategy of manipulating video playbackrates, we considerably outperform video extensions of sophisticated state-of-the-art semi-supervised image recognition methods across multiple diverse benchmark datasets and network architectures. |
A. Sahoo, A. Singh, R. Panda, R. Feris, A. Das; ECCV workshop on Imbalance Problems in Computer Vision (IPCV), 2020.
[Code] [Virtual Presentation]
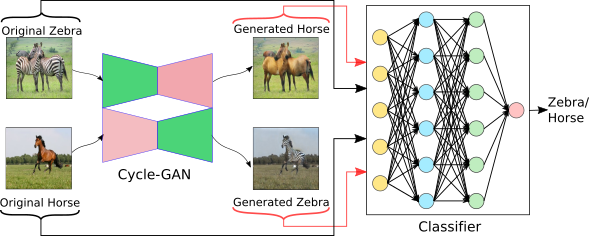 Supervised deep learning based methods though hugely successful suffers a lot from biases and imbalances in training data. In this work we address the performance degradation issue of deep models due to dataset imbalance and study its effect on both deep classification and generation methods. We introduce a joint dataset repairment strategy by combining a neural network classifier with Generative Adversarial Networks (GAN) that makes up for the deficit of training examples from the under-representated class by producing additional training examples. Our proposed approach explores a cycleGAN to translate image from one domain (source) to another domain (target). Instead of using the cycle-GAN as only a component of the classification pipeline, we employ a joint training strategy that first trains the classifier using images generated by the cycle-GAN and then trains the cycle-GAN by back-propagating the classifier loss through it. We show that the combined training helps to improve the robustness of both the classifier and the GAN against severe class imbalance.
Supervised deep learning based methods though hugely successful suffers a lot from biases and imbalances in training data. In this work we address the performance degradation issue of deep models due to dataset imbalance and study its effect on both deep classification and generation methods. We introduce a joint dataset repairment strategy by combining a neural network classifier with Generative Adversarial Networks (GAN) that makes up for the deficit of training examples from the under-representated class by producing additional training examples. Our proposed approach explores a cycleGAN to translate image from one domain (source) to another domain (target). Instead of using the cycle-GAN as only a component of the classification pipeline, we employ a joint training strategy that first trains the classifier using images generated by the cycle-GAN and then trains the cycle-GAN by back-propagating the classifier loss through it. We show that the combined training helps to improve the robustness of both the classifier and the GAN against severe class imbalance.
|
R. Ahmad, M. D. Soltani, M. Safari, A. Srivastava, A. Das; IEEE Access, 2020.
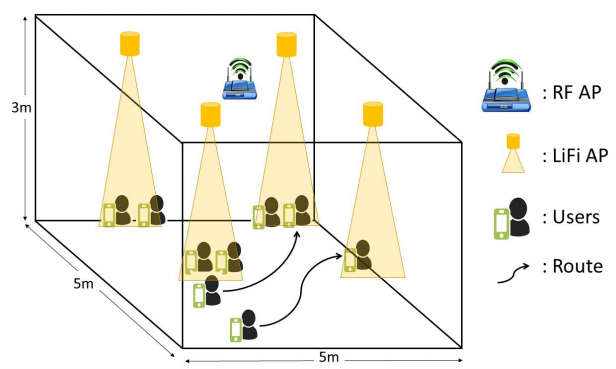 A hybrid network consisting of LiFi (light fidelity) and WiFi is becoming popular compared to standalone LiFi or WiFi only networks due to better coverage of WiFi and high data throughput of LiFi. However, WiFi suffers from low datarates while the LiFi, being dependent on visible light communication (VLC), is prone to blockages. Thus, efficient load balancing is a major challenge in such a hybrid network where user Access Point (AP) selection and resource allocation are two main issues to deal with. In this paper, we have used Reinforcement Learning (RL) based methods for performing the load balancing in a hybrid LiFi-WiFi network. It has been shown that RL based load balancing provides improved average network throughput, user satisfaction, fairness and outage performance. The results are compared against the state-of-the-art signal strength strategy (SSS), an iterative optimization method and exhaustive search. It is shown that the proposed RL method performs closer to the exhaustive search scheme at fairly low complexity and outperforms the rest in most scenarios.
A hybrid network consisting of LiFi (light fidelity) and WiFi is becoming popular compared to standalone LiFi or WiFi only networks due to better coverage of WiFi and high data throughput of LiFi. However, WiFi suffers from low datarates while the LiFi, being dependent on visible light communication (VLC), is prone to blockages. Thus, efficient load balancing is a major challenge in such a hybrid network where user Access Point (AP) selection and resource allocation are two main issues to deal with. In this paper, we have used Reinforcement Learning (RL) based methods for performing the load balancing in a hybrid LiFi-WiFi network. It has been shown that RL based load balancing provides improved average network throughput, user satisfaction, fairness and outage performance. The results are compared against the state-of-the-art signal strength strategy (SSS), an iterative optimization method and exhaustive search. It is shown that the proposed RL method performs closer to the exhaustive search scheme at fairly low complexity and outperforms the rest in most scenarios.
|
H. Xu, X. Sun, E. Tzeng, A. Das, K. Saenko, T. Darrell; IEEE CVPR workshop on Visual Learning with Limited Labels, 2020.
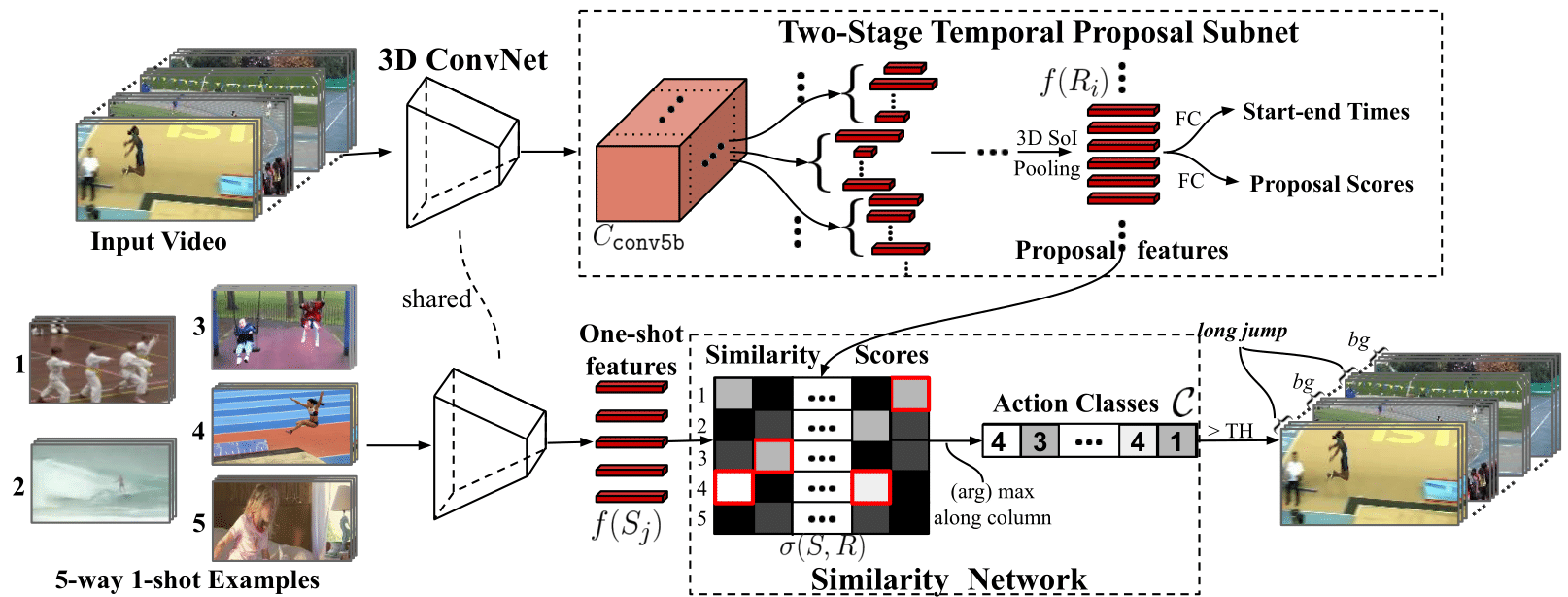 This paper revisits few shot activity detection in videos. This paper builds on the R-C3D paper but addresses the problem of detecting activities in videos when the number of training videos with annotated start and end times of activities is very less. In the proposed approach proposed approach untrimmed videos and a few trimmed videos are passed through a R-C3D backbone temporal proposal network. The features from the generated proposals and the few trimmed videos are compared for similarity to decide the activity labels for the generated temporal proposals. The network is end-to-end trainable with the opportunity to use trimmed videos for pretraining. The work studies the effect of overlap of classes in the trimmed pretraining videos and the few shot untrimmed videos with activity start-end time annotations.
This paper revisits few shot activity detection in videos. This paper builds on the R-C3D paper but addresses the problem of detecting activities in videos when the number of training videos with annotated start and end times of activities is very less. In the proposed approach proposed approach untrimmed videos and a few trimmed videos are passed through a R-C3D backbone temporal proposal network. The features from the generated proposals and the few trimmed videos are compared for similarity to decide the activity labels for the generated temporal proposals. The network is end-to-end trainable with the opportunity to use trimmed videos for pretraining. The work studies the effect of overlap of classes in the trimmed pretraining videos and the few shot untrimmed videos with activity start-end time annotations.
|
H. Xu, A. Das, K. Saenko; IEEE Trans. on Pattern Analysis and Machine Intelligence, 2019.
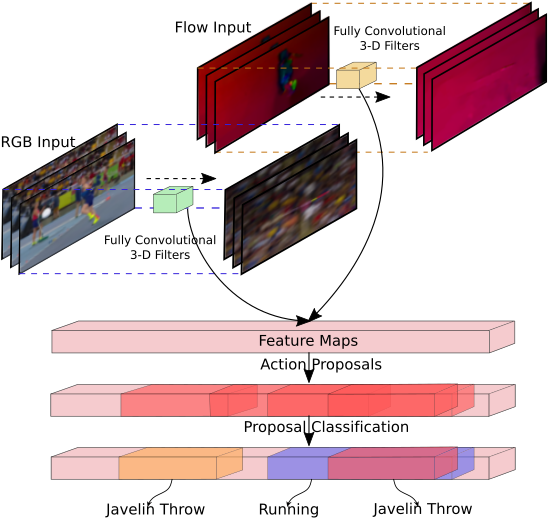 Building on the end-to-end activity detection framework R-C3D (ICCV 2017), this framework detects activities in untrimmed videos by making use of optical flow features in addition to raw pixels in a second stream. This two-stream architecture also explores an online hard example mining strategy to address the extreme foreground-background imbalance that is seen due to the presence of large amount of background frames compared to frames containing activivities in the videos. Instead of heuristically sampling the candidate segments for the final activity classification stage, we rank them according to their performance and only select the worst performers to update the model. This improves the model without heavy hyper-parameter tuning. Extensive evaluations on three diverse activity detection datasets demonstrate the general applicability of our model and the improvement over the original R-C3D architecture.
Building on the end-to-end activity detection framework R-C3D (ICCV 2017), this framework detects activities in untrimmed videos by making use of optical flow features in addition to raw pixels in a second stream. This two-stream architecture also explores an online hard example mining strategy to address the extreme foreground-background imbalance that is seen due to the presence of large amount of background frames compared to frames containing activivities in the videos. Instead of heuristically sampling the candidate segments for the final activity classification stage, we rank them according to their performance and only select the worst performers to update the model. This improves the model without heavy hyper-parameter tuning. Extensive evaluations on three diverse activity detection datasets demonstrate the general applicability of our model and the improvement over the original R-C3D architecture.
|
V. Petsiuk, A. Das, K. Saenko; British Machine Vision Conference, 2018 (Oral)
 We are all seeing the tremendous promise of Deep Learning and AI in different areas of our life - from healthcare to reccomender systems to autonomous driving. As they are being used for a wider array of tasks, and are becoming more pervasive in everyday life, people are starting to ask the question "why"? The decision making process of such systems remains largely unclear and difficult to explain to the end users. In this paper, we address the problem of Explainable AI for deep neural networks that take images as input and output a class probability. Our proposed RISE approach generates an importance map indicating how salient each pixel is for the model’s prediction. In contrast to white-box approaches that estimate pixel importance using gradients or other internal network state, RISE works on black-box models. It estimates importance empirically by probing the model with randomly masked versions of the input image and obtaining the corresponding outputs. We compare our approach to state-of-the-art importance extraction methods using both an automatic deletion/insertion metric and a pointing metric based on human-annotated object segments.
We are all seeing the tremendous promise of Deep Learning and AI in different areas of our life - from healthcare to reccomender systems to autonomous driving. As they are being used for a wider array of tasks, and are becoming more pervasive in everyday life, people are starting to ask the question "why"? The decision making process of such systems remains largely unclear and difficult to explain to the end users. In this paper, we address the problem of Explainable AI for deep neural networks that take images as input and output a class probability. Our proposed RISE approach generates an importance map indicating how salient each pixel is for the model’s prediction. In contrast to white-box approaches that estimate pixel importance using gradients or other internal network state, RISE works on black-box models. It estimates importance empirically by probing the model with randomly masked versions of the input image and obtaining the corresponding outputs. We compare our approach to state-of-the-art importance extraction methods using both an automatic deletion/insertion metric and a pointing metric based on human-annotated object segments.
|
H. Xu, A. Das, K. Saenko; International Conference on Computer Vision, 2017
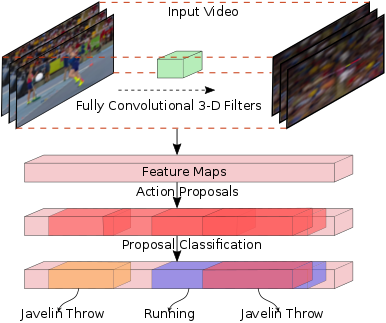 Activity detection in continuous, untrimmed videos have been explored in this work. Unlike activity recognition activity detection is not only classifying actions but also accurately localizing the start and end times of each activity. Inspired by the Faster R-CNN object detection approach, we introduce a new model, Region Convolutional 3D Network (R-C3D), which encodes the video streams using a three-dimensional fully convolutional network, then generates candidate temporal regions containing activities, and finally classifies selected regions into specific activities. The entire model is trained end-to-end with jointly optimized localization and classification losses. Computation is saved due to the sharing of convolutional features between the proposal and the classification pipelines making it fast to detect activities. Extensive evaluations on three diverse activity detection datasets demonstrate the general applicability of our model.
Activity detection in continuous, untrimmed videos have been explored in this work. Unlike activity recognition activity detection is not only classifying actions but also accurately localizing the start and end times of each activity. Inspired by the Faster R-CNN object detection approach, we introduce a new model, Region Convolutional 3D Network (R-C3D), which encodes the video streams using a three-dimensional fully convolutional network, then generates candidate temporal regions containing activities, and finally classifies selected regions into specific activities. The entire model is trained end-to-end with jointly optimized localization and classification losses. Computation is saved due to the sharing of convolutional features between the proposal and the classification pipelines making it fast to detect activities. Extensive evaluations on three diverse activity detection datasets demonstrate the general applicability of our model.
|
R. Panda, A. Das, Z. Wu, J. Ernst, A. Roy-Chowdhury; International Conference on Computer Vision, 2017
[Supplementary]
 Summarizing videos has been, traditionally, studied as an unsupervised problem. Recently, supervision in terms of labeled summary is being used to train video summarization models. Unsupervised models are scalable but are blind to the rich semantic information in terms of human annotation limiting the summarization performance. Supervised approaches improves the performance at the cost of large human annotation effort which makes them non-scalable. In this paper, we propose to identify and model important video segments as the most common activities that maximally drive the video towards a particular category. For this purpose we take a weakly supervised approach where we take a flexible 3D CNN architecture, namely Deep Summarization Network (DeSumNet) which is trained with video category information only. The summary is obtained by finding segments in terms of the CNN derivatives with respect to the video segments. The CNN derivative comes via a single back-propagation pass guided by the category with highest score in the forward pass. The advantage is twofold. Firstly, collecting videos with video-level annotation is less costly than collecting summaries but at the same time it is more informative than unsupervised approaches. Secondly, the method is fast as it generates the summary via one single backpropagation pass. In addition, to unleash the full potential of our 3D CNN architecture, we also explored a series of good practices to reduce the influence of limited training data. Experiments on two challenging and diverse datasets well demonstrate that our approach produces superior quality video summaries compared to several recently proposed approaches.
Summarizing videos has been, traditionally, studied as an unsupervised problem. Recently, supervision in terms of labeled summary is being used to train video summarization models. Unsupervised models are scalable but are blind to the rich semantic information in terms of human annotation limiting the summarization performance. Supervised approaches improves the performance at the cost of large human annotation effort which makes them non-scalable. In this paper, we propose to identify and model important video segments as the most common activities that maximally drive the video towards a particular category. For this purpose we take a weakly supervised approach where we take a flexible 3D CNN architecture, namely Deep Summarization Network (DeSumNet) which is trained with video category information only. The summary is obtained by finding segments in terms of the CNN derivatives with respect to the video segments. The CNN derivative comes via a single back-propagation pass guided by the category with highest score in the forward pass. The advantage is twofold. Firstly, collecting videos with video-level annotation is less costly than collecting summaries but at the same time it is more informative than unsupervised approaches. Secondly, the method is fast as it generates the summary via one single backpropagation pass. In addition, to unleash the full potential of our 3D CNN architecture, we also explored a series of good practices to reduce the influence of limited training data. Experiments on two challenging and diverse datasets well demonstrate that our approach produces superior quality video summaries compared to several recently proposed approaches.
|
V. Ramanishka, A. Das, J. Zhang, K. Saenko; Computer Vision and Pattern Recognition, 2017.
[Project] [Code] [Poster]
 In this work, we propose a deep neural model to extract spatio-temporally salient regions in videos and spatially salient regions in images using natural language sentences as top-down input. We demonstrated that it can be used to analyze and understand the complex decision processes in image and video captioning networks without making modifications such as adding explicit attention layers. Our approach is inspired by the signal drop-out methods used to study properties of convolutional networks. However we extend the idea to LSTM based encoder-decoder models. We estimate the saliency of each temporal frame and/or spatial region by computing the information gain it produces for generating the given word. This is done by replacing the input image or video by a single region and observing the effect on the word in terms of its generation probability given the single region only. Our approach maintains good captioning performance while providing more accurate spatial heatmaps than existing methods.
In this work, we propose a deep neural model to extract spatio-temporally salient regions in videos and spatially salient regions in images using natural language sentences as top-down input. We demonstrated that it can be used to analyze and understand the complex decision processes in image and video captioning networks without making modifications such as adding explicit attention layers. Our approach is inspired by the signal drop-out methods used to study properties of convolutional networks. However we extend the idea to LSTM based encoder-decoder models. We estimate the saliency of each temporal frame and/or spatial region by computing the information gain it produces for generating the given word. This is done by replacing the input image or video by a single region and observing the effect on the word in terms of its generation probability given the single region only. Our approach maintains good captioning performance while providing more accurate spatial heatmaps than existing methods.
|
2016:
A. Das, R. Panda, A. Roy-Chowdhury; Computer Vision and Image Understanding, 2016.
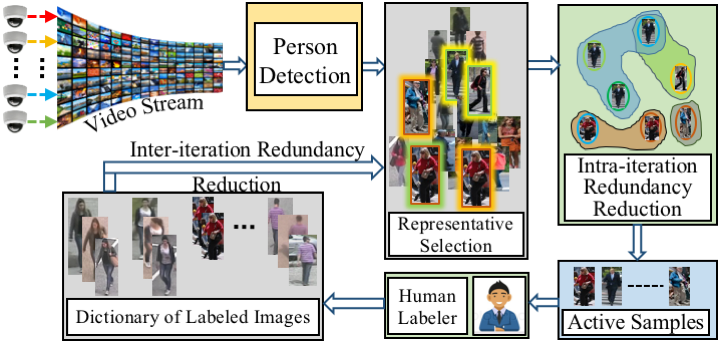 In this paper, we addressed the problem of online learning of identification systems where unlabeled data comes in small minibatches.Though labeling manually is an indispensable part of a supervised framework, for a large scale identification system labeling huge amount of data is a significant overhead. The goal is to involve human in the loop during the online learning of the system but at the same time reduce human annotation effort without compromising the performance. For large multi-sensor data as typically encountered in camera networks, labeling a lot of samples does not always mean more information, as redundant images are labeled several times. In this work, we propose a convex optimization based iterative framework that progressively and judiciously chooses a sparse but informative set of samples for labeling, with minimal overlap with previously labeled images. We demonstrate the effectiveness of our approach on multi-camera person reidentification datasets, to demonstrate the feasibility of learning online classification models in multi-camera big data applications and show that our framework achieves superior performance with significantly less amount of manual labeling.
In this paper, we addressed the problem of online learning of identification systems where unlabeled data comes in small minibatches.Though labeling manually is an indispensable part of a supervised framework, for a large scale identification system labeling huge amount of data is a significant overhead. The goal is to involve human in the loop during the online learning of the system but at the same time reduce human annotation effort without compromising the performance. For large multi-sensor data as typically encountered in camera networks, labeling a lot of samples does not always mean more information, as redundant images are labeled several times. In this work, we propose a convex optimization based iterative framework that progressively and judiciously chooses a sparse but informative set of samples for labeling, with minimal overlap with previously labeled images. We demonstrate the effectiveness of our approach on multi-camera person reidentification datasets, to demonstrate the feasibility of learning online classification models in multi-camera big data applications and show that our framework achieves superior performance with significantly less amount of manual labeling.
|
A. Chakraborty, A. Das, A. Roy-Chowdhury; IEEE Trans. on Pattern Analysis and Machine Intelligence, 2016.
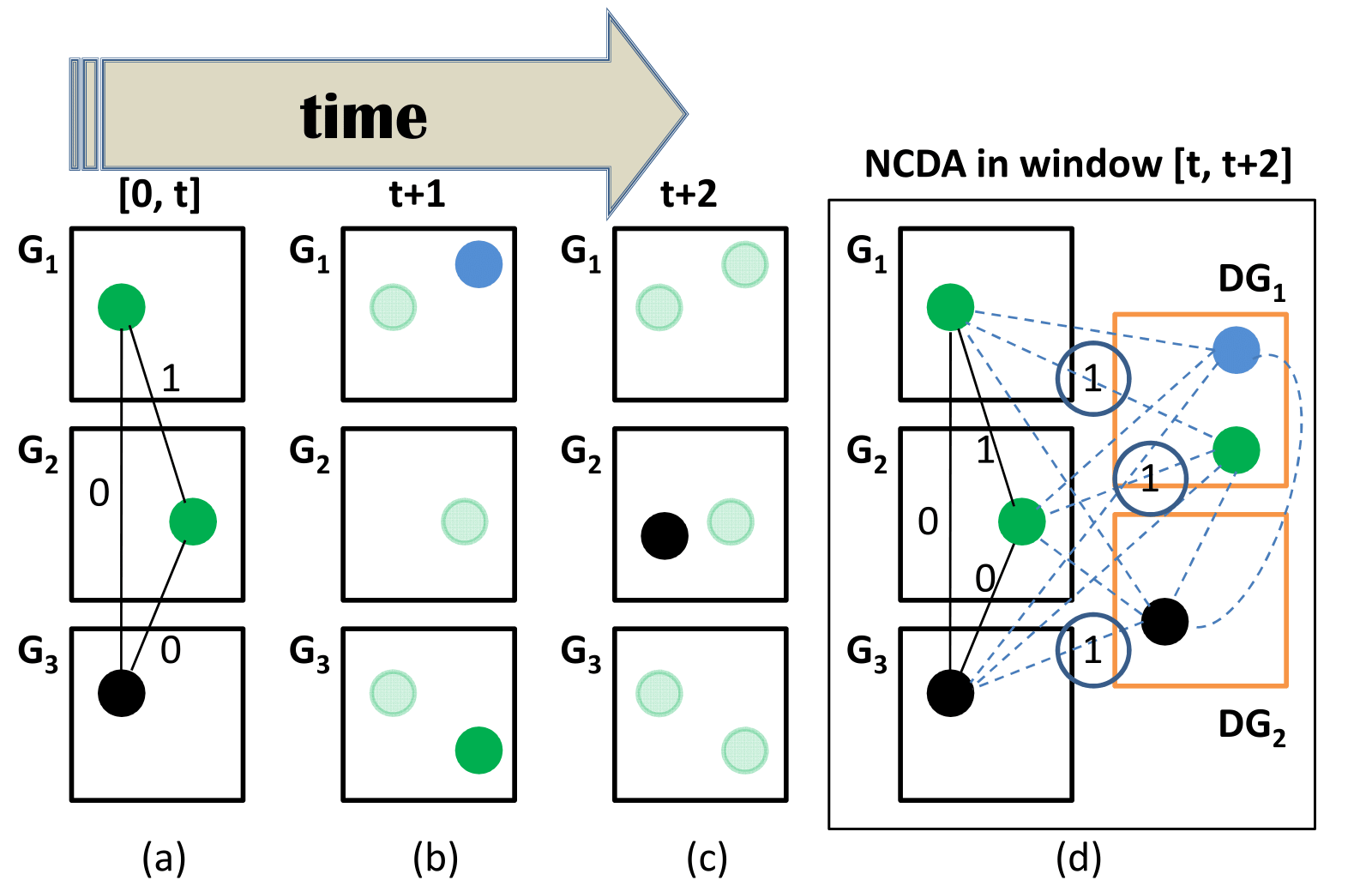 |
We extend our previous work on network consistent re-identification to more general online data association exploring consistency among different agents at the same time. The more general Network Consistent Data Association (NCDA) method now, can dynamically associate new observations to already observed data-points in an iterative fashion, while maintaining network consistency. We have also extended the application area to spatiotemporal cell tracking of Arabidopsis SAM images. |
N. Martinel, A. Das, C. Micheloni, A. Roy-Chowdhury; European Conference in Computer Vision, 2016.
[Supplementary]
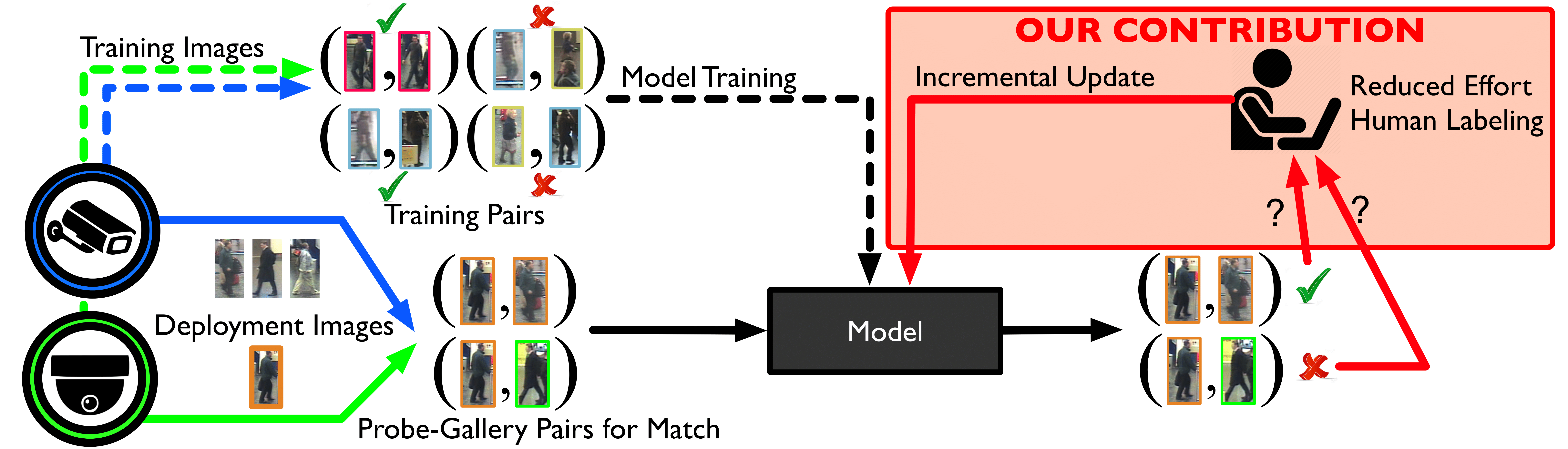 In this work we have addressed the problem of temporal adaptation of person re-identification systems. We study how to adapt an installed system from data being continuously collected by incorporating human in the loop. However, manual labor being costly, we device a graph-based approach to present the human only the most informative probe-gallery matches that should be used to update the model. Using these probe-gallery image pairs the system is trained in an incremental fashion. For this we introduced a similarity-dissimilarity learning method which is solved using a stochastic alternating directions methods of multipliers. Results on three datasets have shown that our approach performs on par or even better than state-of-the-art approaches while reducing the manual pairwise labeling effort by about 80%.
In this work we have addressed the problem of temporal adaptation of person re-identification systems. We study how to adapt an installed system from data being continuously collected by incorporating human in the loop. However, manual labor being costly, we device a graph-based approach to present the human only the most informative probe-gallery matches that should be used to update the model. Using these probe-gallery image pairs the system is trained in an incremental fashion. For this we introduced a similarity-dissimilarity learning method which is solved using a stochastic alternating directions methods of multipliers. Results on three datasets have shown that our approach performs on par or even better than state-of-the-art approaches while reducing the manual pairwise labeling effort by about 80%.
|
V. Ramanishka, A. Das, D. H. Park, S. Venugopalan, L. A. Hendricks, M. Rohrbach, K. Saenko; ACM Multimedia, 2016 (MSR Video to Language Challenge).
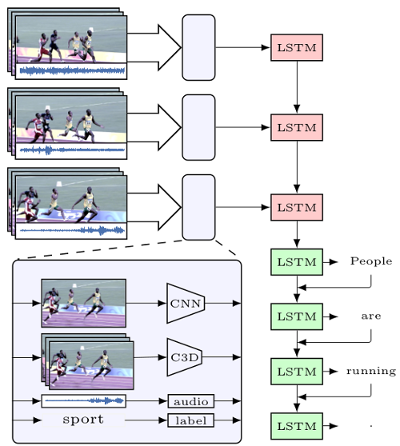 Understanding a visual scene and expressing it in terms of natural language descriptions is a challenging task and has especially drawn a lot of attemtion among the researchers. In this paper, we addressed the problem of describing long videos in natural language using multiple sources of information. In particular, we propose a sequence-to-sequence model which uses audio and the topic of the video in addition to the visual information to generate coherent descriptions of videos “in the wild”. In addition, we show that employing a committee of models where each model is an expert in describing videos from a specific category is advantageous than a single model trying to describe videos from multiple categories. Extensive experiments on the challenging MSR-VTT dataset are carried out to show the superior performance of the proposed approach on natural videos found in the web which comes with several challenges including diverse content and diverse as well as noisy descriptions. We secured third position in the MSR Video to Language Challenge organized with ACM MM, 2016.
Understanding a visual scene and expressing it in terms of natural language descriptions is a challenging task and has especially drawn a lot of attemtion among the researchers. In this paper, we addressed the problem of describing long videos in natural language using multiple sources of information. In particular, we propose a sequence-to-sequence model which uses audio and the topic of the video in addition to the visual information to generate coherent descriptions of videos “in the wild”. In addition, we show that employing a committee of models where each model is an expert in describing videos from a specific category is advantageous than a single model trying to describe videos from multiple categories. Extensive experiments on the challenging MSR-VTT dataset are carried out to show the superior performance of the proposed approach on natural videos found in the web which comes with several challenges including diverse content and diverse as well as noisy descriptions. We secured third position in the MSR Video to Language Challenge organized with ACM MM, 2016.
|
R. Panda, A. Das, A. Roy-Chowdhury; IEEE International Conference on Image Processing, 2016.
[Supplementary]
 In this paper, we addressed the problem of summarizing long videos viewed from multiple cameras into a single summary. Summarizing multi-view videos has its own challenges which makes it a completely separate problem than the traditional single view video summarization problem. The videos in different views contain different illumination, pose etc. and the lack of time synchronization between different views also makes the problem significantly more challenging. On the other hand, judicious exploration of inter-view content correlations is required so that important information is collected without significanr overlap. We address the problem by first learning a joint embedding space for all the videos such that content correlations between frames of the same view as well as between frames from different views are preserved in the learned embedding space. The two types of content correlations are formulated using two different kernels keeping in mind the fact that the local structure (inside each view) of the frames in terms their proximity should not get destructed while trying to embed videos from different views to a commopn space. The resulting non-convex optimization was solved using a state-of-the-art Majorization-Minimization algorithm. After representing all videos in a joint embedding space, a standard sparse code based representation selection algorithm is applied to get the joint summary. We validate the approach by experimenting on three publicly available benchmark datasets showing improvements over the state-of-the-art.
In this paper, we addressed the problem of summarizing long videos viewed from multiple cameras into a single summary. Summarizing multi-view videos has its own challenges which makes it a completely separate problem than the traditional single view video summarization problem. The videos in different views contain different illumination, pose etc. and the lack of time synchronization between different views also makes the problem significantly more challenging. On the other hand, judicious exploration of inter-view content correlations is required so that important information is collected without significanr overlap. We address the problem by first learning a joint embedding space for all the videos such that content correlations between frames of the same view as well as between frames from different views are preserved in the learned embedding space. The two types of content correlations are formulated using two different kernels keeping in mind the fact that the local structure (inside each view) of the frames in terms their proximity should not get destructed while trying to embed videos from different views to a commopn space. The resulting non-convex optimization was solved using a state-of-the-art Majorization-Minimization algorithm. After representing all videos in a joint embedding space, a standard sparse code based representation selection algorithm is applied to get the joint summary. We validate the approach by experimenting on three publicly available benchmark datasets showing improvements over the state-of-the-art.
|
R. Panda, A. Das, A. Roy-Chowdhury; International Conference on Pattern Recognition, 2016.
 In this paper, the problem of summarizing long videos viewed from multiple cameras is addressed by forming a joint embedding space and solving an eigenvalue problem in that embedding space. The embedding is learned by exploring intra view similarities (i.e., between frames of the same video) and also inter-view similarities (i.e., between frames of different videos looking roughly at the same scene). To preserve both types of similarities, a sparse subspace clustering approach is used with objectives and constraints changed suitably to fit the different needs for the two different scenarios. We get the embedded representation of all the frames from all the videos by an unification of the two types of similarities using block matrices. This leads to solving a standard eigenvalue problem. After getting the embeddings, we apply a similar procedure of sparse representative selection as is done in the above paper to get the joint summary. Experimentations on both multiview and single view datasets show the applicability of this generalized method for a wide application area.
In this paper, the problem of summarizing long videos viewed from multiple cameras is addressed by forming a joint embedding space and solving an eigenvalue problem in that embedding space. The embedding is learned by exploring intra view similarities (i.e., between frames of the same video) and also inter-view similarities (i.e., between frames of different videos looking roughly at the same scene). To preserve both types of similarities, a sparse subspace clustering approach is used with objectives and constraints changed suitably to fit the different needs for the two different scenarios. We get the embedded representation of all the frames from all the videos by an unification of the two types of similarities using block matrices. This leads to solving a standard eigenvalue problem. After getting the embeddings, we apply a similar procedure of sparse representative selection as is done in the above paper to get the joint summary. Experimentations on both multiview and single view datasets show the applicability of this generalized method for a wide application area.
|
2015:
A. Das, R. Panda, A. Roy-Chowdhury; IEEE International Conference on Image Processing, 2015.
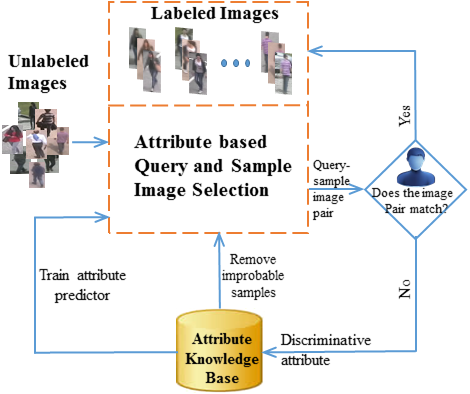 |
Most traditional multi-camera person re-identification systems rely on learning a static model on tediously labeled training data. Such a framework may not be suitable for situations when new data arrives continuously or all the data is not available for labeling beforehand. Inspired by the value of information active learning framework, a continuous learning person re-identification system with a human in the loop, is explored in this work. The human in the loop not only provides labels to the incoming images but also improves the learned model by providing most appropriate attribute based explanations. These attribute based explanations are used to learn attribute predictors along the way. The overall effect of such a stratgey is that the machine assists the human to speed up the annotation and the human assists the machine to update itself with more annotation in a symbiotic relationship. In this paper, we validate our approach using a benchmark dataset. |
A. Das, A. Chakraborty, A. Roy-Chowdhury; European Conference in Computer Vision, 2014.
[Supplementary] [Dataset] [Code] [Bibtex] [Poster] [video spotlight]
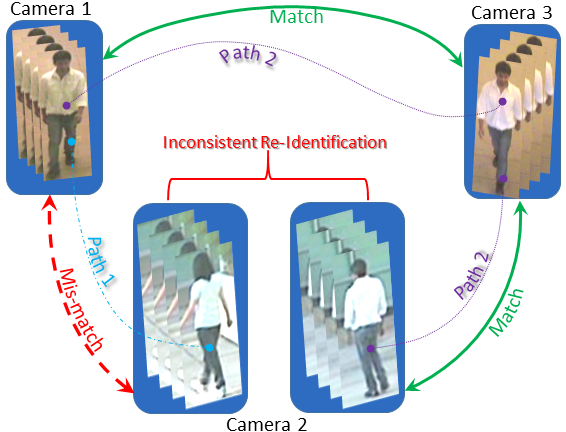 |
Most existing person re-identification methods are camera pairwise. These do not explicitly result in consistent re-identification across a camera network and leads to infeasible associations when results from different camera pairs are combined. In this paper, we propose a network consistent re-identification (NCR) framework. This is formulated as an optimization problem that not only maintains consistency in re-identification results across the network, but also improves the camera pairwise re-identification performance between all the individual camera pairs. The problem is solved as a binary integer program, leading to a globally optimal solution. |
A. Das, N. Martinel, C. Micheloni, A. Roy-Chowdhury; IEEE Trans. on Pattern Analysis and Machine Intelligence, 2015.
[Supplementary]
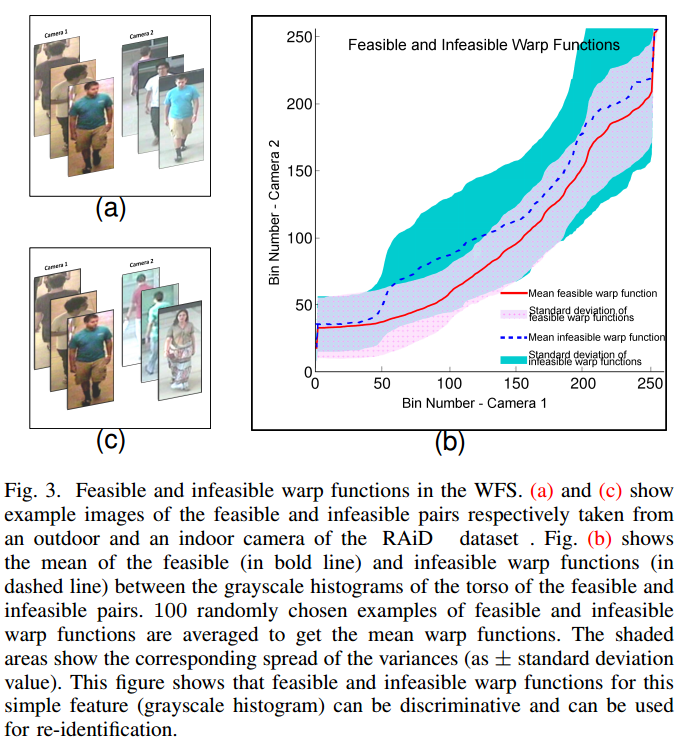 |
One of the major problems in the domain of person re-identification is the transformation of features between cameras. In this work we model this transformation by warping feature space from one camera to another motivated by the principle of Dynamic Time Warping (DTW). The warp functions between two instances of the same target are feasible warp functions while those between instances of different targets are infeasible warp functions. A function space, called the Warp Function Space (WFS), composed of these feasible and infeasible warp functions is learned and tperson re-identification is addressed as mapping a test warp function onto the WFS and classifying it as belonging to either the set of feasible or infeasible warp functions. Through extensive experimentations on 5 benchmark datasets our approach is shown to be robust especially with respect to severe illumination and pose variations. |





