
Exploring optimizations such as kernel fusion, coarsening, tiling etc. for HPC applications like object detection, speech recognition, DNN training etc.
LEARN MOREScheduling mechanisms for heterogeneous large scale clusters and embedded GPGPU platforms comprising multiple devices such OCPUs, iGPUs,Exploring optimizations FPGAs etc.
LEARN MOREA repository of online learning articles, books, libraries pertaining to CUDA/OpenCL and the latest HPC news facilitating individuals to explore a career in GPGPU Programming and Research
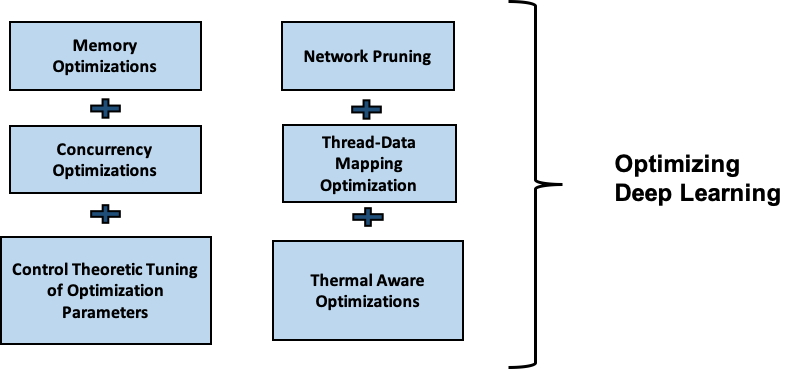
LEARN MOREThe landscape of deep learning has witnessed a paradigm shift in recent years with the advent of compiler tool chains with dedicated graphical IRs, custom made accelerators tuned for tensor computation and algorithmic optimizations for both training and inference workloads on both heterogeneous compute clusters and embedded platforms. In this context, we are also exploring optimizations for deriving novel scheduling solutions for mapping deep learning workloads on heterogeneous architectures. For significantly large training workloads, the primary bottleneck is the on-chip memory of accelerators. In this regard we are investigating scheduling techniques of asynchronously prefetching and offloading memory in parallel with the computation for accelerating the training process. For inference pipelines, the primary objective would be to ensure that thermal degradation of the platform does not occur. In this regard, we are investigating novel GPGPU optimizations such as kernel fusion and coarsening for mapping the pipeline efficiently on an embedded platform. For both styles of optimizations, predictive modelling and control theoretic solutions are being envisaged for facilitating dynamic and adaptive mapping of computation kernels pertaining to deep learning workloads.
Recent efforts towards application scheduling on heterogeneous multiprocessor architectures typically consider applications to be represented as directed acyclic graphs (DAGs). Each application DAG is annotated at the task level with relevant execution time information that is leveraged by scheduling algorithms (List or Clustering based) to ascertain near optimal schedules at runtime. However, given an online setting, where applications are submitted by multiple users and the types of applications are not restrictive, the chances of knowing execution time information for every program is highly unlikely. In this context, we propose a class of intelligent algorithms for heterogeneous CPU-GPU platforms that leverages static analysis methodologies coupled with machine learning and ascertains how based on static program structure of tasks, device assignments should be made at runtime. This methodology helps in bypassing the requirement for profiling based offline execution time analysis thus making it applicable in an online scheduling scenario. We model applications as data parallel task graphs using the OpenCL programming model leveraging its device independent portability feature. The scheduling algorithms (list and clustering) consider both coarse-grained (where operations of kernels are mapped in its entirety to a device) and fine-grained mapping decisions (where read, write and execute operations are interleaved in parallel).

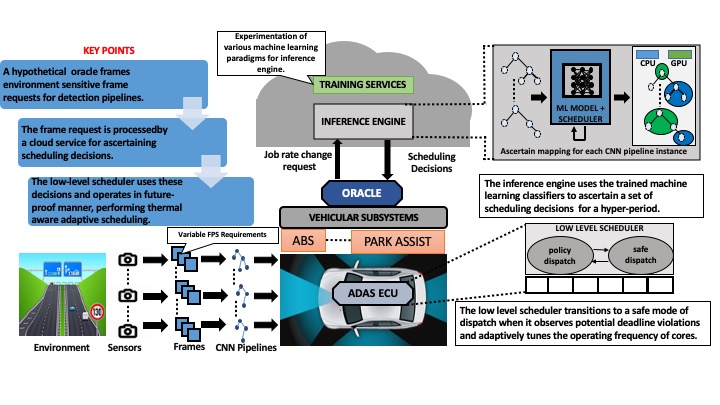
An ADAS system constitutes multiple object detection pipelines that process sensor data periodically leveraging state of the art Deep Neural Networks (DNNs) and Convolutional Neural Networks(CNNs). The pipelines are used to detect objects in the vicinity and accordingly dispatch commands to other vehicular subsystems such as park assist, anti-lock braking systems etc. for taking relevant actions. Therefore, there exists a natural requirement for real time guarantees for executing these object detection pipelines.
Furthermore, such pipelines possess time varying dynamic FPS requirements dictated by different driving contexts. Given the set of ADAS detection workloads, designing automotive computing solutions with the ability to sustain the maximum FPS requirements of all detection pipelines simultaneously may lead to over-provisioning of resources on a restricted memory architecture, and also increased power consumption and thermal aging of the heterogeneous platform.
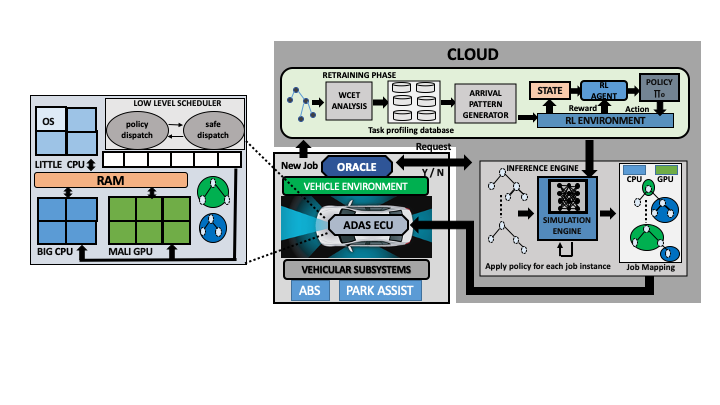
The present work proposes an intelligent runtime system which can manage the mapping and scheduling of ADAS detection pipelines in next-generation automotive embedded platforms in a self-learning fashion so that the time varying dynamic detection requirements of existing pipelines are efficiently managed while maintaining real time guarantees. Since investigating every possible mapping decision imposes a considerably large searchspace of decisions to be evaluated for finding an optimal solution,we design Reinforcement Learning based schemes for predicting task-device mapping decisions for each pipeline subject to dynamic FPS requirements over time.
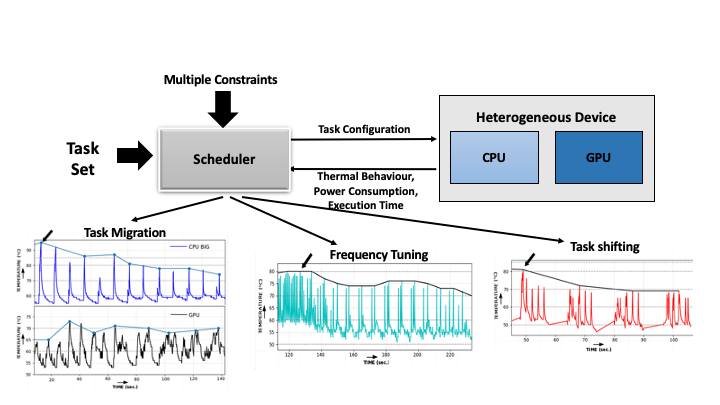
Modern mobile platforms are equipped with heterogeneous multiprocessor system-on-chip (MPSoC) where the architecture is becoming increasingly complex and heterogeneous having multiple compute elements with varying compute capabilities. They can include multicore big-LITTLE CPUs, accelerators capable of general-purpose computing like graphic processing units (GPUs), and field programmable gate arrays (FPGAs) or digital signal processor (DSP). Increasingly smaller chip size and functional complexity leads to increase in the power density which in turn results in chip overheating which degrades its reliability, and may risk physical safety. Due to the absence of active cooling measures in such mobile platforms, thermal constraints are much more stringent . Thus, in recent times temperature-aware resource scheduling that can maintain on-chip thermal constraints as well as application timing constraints has become a key system design objective in heterogeneous embeded platform with varying compute elements. We are actively researching on efficent scheduling mechanisms that can determine optimal or near-optimal assignment of tasks to devices with multiple control values of the thermal features in heterogeneous embedded processors having multiple constraints such as meeting deadline, power enveloping etc.
In the past few years, OpenCL has emerged as a widely used parallel programming standard for high perfor-
mance computing on heterogeneous platforms comprising processors of widely varying architectures.
The programming standard offers program portability across an array of
different processor architectures e.g., general purpose (CPU), data parallel (GPU), task
parallel (CELL/B.E.) etc. The OpenCL API provides the programmer with a
vast array of options to write data-parallel programs efficiently for heterogeneous
architectures. However there exists a steep learning curve in learning the low level directives offered by the
OpenCL API completely. In addition to getting acquainted with the API, the programmer is burdened with the
task of ascertaining target device characteristics and writing efficient code for utilizing the varied
processing elements in the heterogeneous system to their complete potential. Our framework is based on
the PyOpenCL python package and provides user friendly abstractions over the underlying API for designing
efficient solutions much faster.
The primary goal of PySchedCL is to provide a platform for rapid prototyping of
high performance applications as well as a research tool for experimenting various scheduling and mapping policies
of multiple OpenCL applications for different heterogeneous platforms. The framework leverages a kernel specification scheme that specifies
information regarding the host side management for the execution of an OpenCL kernel. Given the corresponding specification
file for a kernel, the framework is capable of distributing the computation across the devices of the target heterogeneous architecture.
The salient features of the framework is represented in the following figure and discussed below.
The current version of PySchedCL provides a scheduling engine that may be leveraged for the following tasks.
In addition to the above tasks, the tool provides a rich API and an extensive documentation for extending the current capabilities of the framework with ease.

Our Testbeds
Hardware