ADT Computing Paradigm
Lecture 6-9
- Abstract data type (ADT) : It is user defined data type along with the operations it supports. We should only be able to do operations that are defined on it and not be able to do any other operation that is not defined. Contrast of this is built in data type.
- What is ADT paradigm of computing?
- What is expected in ADT?
- How is it different from modular programing?
- how is ADT code different from modular C- code?
- Evolution of ADT (in C language) :
- Programing Language
- Procedural Language
- Modular Language
- ADT
- Till ADT everything is static type.
- Static means information known at compile time while dynamic means information known at run time.
- Static type means object’s type is same at compile time and run time.
- ADT is also called as object based computing where object is any entity that has defined structure and behaviour.
- In ADT object has same static and dynamic type while in object oriented computing, object can have different compile and dynamic type.
- If everything can be done using static type and ADT then there is no need to use object oriented programming.
- Before starting with ADT Computing we will take look at programmer’s point of view.
- We will not focus on syntax but on the semantics and its implementation.
- We will look at implementation one layer above the compiler, i.e. how to convert object oriented program to C language.
- C language will be the medium of instructions throughout the course.
- Object : A programmable entity, which consumes memory is called an object or a variable.
- #define pa 100
- int a;
- MyType mt;
- MyClass mobj;
In the statements above except for pa (which is only text substituted to 100) rest all consume memory and hence they are called objects/variables.
- Every object in memory has a structure and behaviour.
- Structure of an object is a bit string in memory.
- To distinguish between two different object we have some semantics associated with the structure. e.g. 4 byte Integer and 4 byte Float will look the same but they will have different semantics. This semantic is drawn from the type of an object which is Integer and Float in above example.
- Type Casting : We can change the behaviour of one object to behaviour of another object using type casting. Consider the example below:
MonkeyStruct *mnkS = (MonkeyStruct*)malloc(sizeof(MonkeyStruct));
void *vS = (void *)mnkS;
ManStruct * manS = (ManStruct *)vS;
Here we have 2 objects mnkS and manS. Assuming both have same structural semantics, then monkey will assume behaviour of a man.
- Advantage : It adds to the flexibility of the language and good for programmer. A good language should allow such type casting and a good system should know there exist such flexibility.
- Disadvantage : It is prone to errors.
- Better Programming Practices
- For understanding the better programming practices we look at simple array implementation of a stack -
#define Size 100
int array[Size];
int top = 0;
void push(int a) { array[top++] = a:}
int pop () { return array[--top]; }
int Is_Empty () { return (top == 0) ? 1 : 0; }
int Is_Full () { return (top == Size – 1) ? 1 : 0; }
Below we discuss the issues in the above implementation and improve the code to make it better reusable.
- Issue 1: Invalid memory access
- If we push an element when top = 100 or pop when top =0 then it will access invalid memory location.
- To avoid this we identify the read write operations that change the stack (i.e. push and pop ) and add pre and post conditions to avoid invalid memory access as shown below :
void push(int a) {
if Is_full() NO_PUSH; // pre-condition
array[top++] = a:
Is_Empty = FALSE //post-condition
}
Similarly for pop operation check and update the empty condition.
- Issue 2 : Allocate Dynamically
- Applications may demand stacks of varying sizes. In that case we can implement stack using linked list instead of an array.
- Advantage : No issue of invalid memory access, so no need to check Is_full condition.
- Disadvantage : Memory will be fragmented. Additional work is needed to handle the pointers
- Issue 3 : Allocate Contiguous Memory
- Applications may demand stacks of varying sizes. In that case memory will be allocated dynamically as :
typedef struct stag{
int * v;
int MaxSize;
int * top;
} Stack;
Creat_initialize_Stack(Stack *S, int MaxSize){
v = (int *) calloc ( sizeof (int), MaxSize)};
- Advantage : Same program can have stacks of different sizes
- Disadvantage : Size of the stacks need to be predicted before creating them.
- Issue 4 : Random Access of Stack Elements
- Even if stack is implemented either by static allocation or dynamic allocation of memory, we can change the top of the stack without the push, pop functions because it is basically an array implementation.
- To avoid this we should not allow the programmer to access the array directly. This can be achieved by abstraction and encapsulation.
- Abstraction : Whatever we want to do with the structure should be well defined.
- Encapsulation : All implementation details must be hidden (or encapsulated) from the user.
- Java has a protocol where object created should be initialised through constructor but C does not have any such protocol to guarantee it.
- Typecasting : In perspective of ADT
- Typecasting can cause various types of errors
- Type I : No Error but unexpected behaviour
- It is when both entities have similar structural semantics.
- One entity behaves like another entity
- In our example: man will behave like a monkey but will not give any kind of error.
- Type II : No compilation error but runtime error
- When both the entities have matching fields then it does not give any compilation error.
- As semantics are different it may give runtime error or unexpected output.
- This is most common type of error which can happen as it can not be caught during compilation.
- Type III : Compilation error
- This error will occur when the two entities have different data fields.
- It is most uncommon and not possible unless one code is very badly written without understanding.
- C language is powerful because it allows typecasting but at the same time prone to above types of errors.
- For a computing application
- We must identify the collection of data items
- e.g. for a Point it’s x-coordinate and y-coordinate .
- Also identify the basic operations on them
- e.g for a Point : move,translate,scale,rotate etc.
- For solving the problem we must decide the implementation details of how to organise the data and how to process the data.
- Question : Are the following data types same or different ?
Struct Point2D {float x, y};
Struct Point2D {float r, theta};
- Solution : Both define the same concept which is 2D point that can be moved, translated,scaled or rotated but both have different implementations, one is cartesian and other is polar. So one cannot replace the other.
- Client application does not care about the implementation details but only cares about the concept. This is called abstraction
- In concept of abstraction user only want to know WHAT a data type can do and HOW it can do is hidden from the user.
- Abstraction means to define the data structure and the operations while Encapsulation hides the organisation of data structure and implementation of operations from the user.
- Goal of software design is to reduce the complexity of system through abstraction.
- Abstract Data Type : It is a data type where data structure and operations are specified independent of its implementation.
Point2D {
// A 2-d point exists somewhere in the plane, …
float x;
float y;
float r;
float theta;
// ... can be created, …
Point(); // new point at (0,0)
Point(x, y); // new point with Cartesian co-ord
Point(r, theta); // new point with Polar co-ord
// ... can be moved, …
void translate(float delta_x, float delta_y);
void scaleAndRotate(float delta_r, float delta_theta);
// ... can be accessed,
float get_x (Point P); float get_y (Point P);
float get_r (Point P); float get_theta (Point P);
}
- Here 2D point is implemented in both cartesian and polar representation and therefore has some redundancy.
- Redundancy makes the implementation of operations easier as translate is easy to implement in cartesian while scale and rotate in polar
- Redundancy can lead to inconsistency and hence to avoid it cartesian constructor must internally set the polar coordinates and vice versa. Also we cannot have constructor of cartesian and polar at same time as both have same types of parameters i.e. (float,float). We will have to create different data types for each like cart-2dpoint and polar-2dpoint.
- In ADT client can perform only those operations on the object which are provided by the abstraction layer
- In computing data can be viewed from three perspective
- Application level : As data within a particular problem or application.
- Logical level : As data values(not types) and set of operations on them.
- Implementation level : As representation of structure holding the data items and coding of operations in programming language.
- An abstract data type is a data type packaged with the operations that are meaningful for the data type. Whatever is not defined, should not operate on the data type.
- We then encapsulate the data and the operations on the data and hide them from the user.
- An ADT is :
- Declaration of data,
- Declaration of operations, and
- Encapsulation of data and operation.
- Model of an ADT:
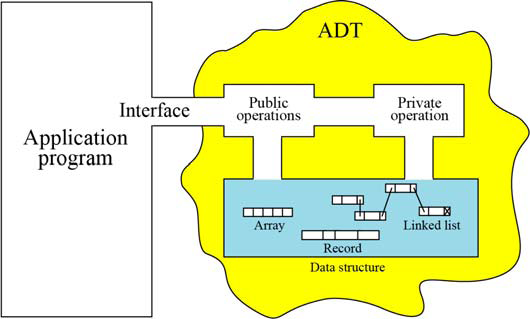
- In ADT we have all the data structures private while operations can be private or public.
- Private operations are required internally and not visible to application program e.g converting polar to cartesian. Interface will have all public operations visible to application program e.g. set_x,get_x etc.
- C language provides this feature in limited way using extern and static.
- ADT,API’s and Standard Interfaces
- They should not allow the application program to directly access the data structure. All references and manipulation of data structure should be through well defined interfaces.
- In well defined interfaces, operations should have same name and signature across all implementations.
- High level languages provide built-in ADTs like C lib (C),STL (C++), APIs/Collections(Java)
- Suppose we want to create stack for int,float,strings. Then the operation and the behaviour of stack will be same but signature of operations will vary.
- Programing language system should allow us to write one code and apply it to any data type. e.g sqrt (for int), sqrtf (for float)
- We can copy and paste the code but it is prone to errors so we have generic code for ADTs. Generic code allows to generalize one set of code by making it a template and apply it to any specific data type. (Note: any data type means not all but with some restrictions like sorting can be generic for Int and Float but for String we will have to define comparison operator for comparing two strings)
- Type itself if a parameter i.e. Parameterised Type e.g. Stack <T> where T is parameter.
- Generic Structural Arrangement of data
- Consider container or collection i.e. data arranged in sequence. It can be a list with basic operations like add, del, next, predecessor, traverse
- Now we can have different data structures with same ADT like queue or tree.
- Challenges in implementing same ADT for different data structures are
- How to match the signatures of the operations for different data structures ?
- …
- Reusable components of software system
- Design : design patterns can be reused.
- Source code : We are studying mainly this reusable component.
- Binary code : reusable libraries. beyond scope of this course
- Generic-ity: There are 2 dimensions of genericity
- Generic Programming : Define the code once and use for multiple data types
e.g. define stack for int, float, double etc.
- Generic Algorithms : Define the algorithm once and use for multiple structural arrangement of data called as generic structure.
- C++ containers : Vectors, List, Arrays etc. of objects
- Java Collections : Set, Queue, Deque etc.
- Interface consists of ADT operations representing the generic behaviour required by an application. It isolates the application program from the generic structure implementation.System is transparent of the data structure
- Hence, good software system must have separate interface and implementation to allow generic algorithm.
- C++ became very powerful in 1997 after adding generic algorithm.
- Three types of parameter:
- Value as a parameter : Simple functions or methods defined once can be used for multiple values.
- Type as a parameter : Same as Generic Programming. Also known as Template or parameterized type.
- Container as a parameter : Same as Generic Algorithm that parameterizes the algorithm by container.
- Data abstraction means to think what we can do to the data independently of how to do it. It allows to implement data structure independent of rest of solution.
- Irrespective of how the data structure is implemented, ADT should provide a wqay to perform following operations on it - add, delete, find, retrieve,sort items etc.
- How to implement generic algorithms ?
- It is possible due to iterators. They iterate through the elements to manipulate the sequence. Irrespective of the data structure it allows to move next or previous.
- Iterator needs to know the begin, end and data structure. Different data structures will have different code of iterator but same interface.
- Therefore main job is to to define the container and fix the iterator
template<class In,class Out> void copy(In from, In too_far, Out to)
{
while(from != too_far)
{
*to = *from;
++to;
++from;
}
}
Here In and Out are the template parameters. to and from are current iterator pointers. copy function copies element pointed by current iterator pointers from one structure to another and increment the iterator to point the next element.This algorithm is independent of the underlying structure. ++ is implemented as operator overloading as depending on the structure it will perform increment operation.
C++ support operator overloading. Java supports inbuilt operator overloading but does not allow programmer to implement it.
complex ac[200];
void g(vector<complex>& vc, list<complex>& lc)
{
copy(&ac[0],&ac[200], lc.begin()); //copy from array to list of complex
copy(lc.begin(),lc.end,vc,begin()); //copy from list to vector
}
Here first call to copy copies the complex numbers form array of complex numbers ot list of complex numbers. Second call copies the complex numbers from list of complex numbers to vector of complex numbers. Thus the code is transparent to the underlying structure of the container.
- Java collection interface includes following operations:
- boolean isEmpty()
- int size()
- boolean add(Object x)
- boolean contains(Object x)
- boolean remove(Object x)
- void clear()
- Object[] toArray()
- Iterator iterator()
- ADT: a set of data-management operations together with the data values upon which they operate
- An ADT should be fully defined before any implementation decisions
- Hide an ADT’s implementation
- Generic Programming:
- One data structure; many types : one interface
- Many data structures; many types: one interface
- Data abstraction controls the interaction between a program and its data structures.