IndicView : Because Language is no more a Barrier
Objectives
The primary aim of the project is to build an application that will be helpful in converting snippets of text written in Indic scripts to other languages. The end product for this project is a mobile app as well as a web application that will extract Hindi text from images and convert it to English.
This project is made keeping in mind the difficulties faced by non-Hindi speakers in understanding the text written in Hindi. It can be used to convert the manuscripts, news, books, magazines or billboards written in Hindi into equivalent English.
Results Planned to Achieve
- A web application where a user can upload photos (Hindi Text) and see the translated English text.
- An android application where clicked photos (Hindi Text) will be translated and shown.
- Testing under different scenarios like lighting conditions and
computing the accuracies and comparing with the basic Tesseract.
- The translated text should be of the same format as the source.
Approach
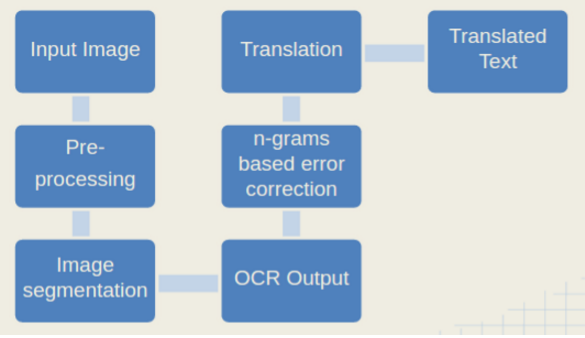
|
The figure on the left shows the workflow of the proposed approach. We use the tesseract-ocr from Google as our main component but pre-process the image before giving it as input to Tesseract to improve the overall accuracy of the OCR. Once we obtain the OCR output, we do a post-processing step for error correction using language modeling. This text is then passed on to a Translation API and the translated text is shown to the user.
|
Below, we briefly describe various components used in our approach.
Pre-Processing of input image before passing it on to Tesseract
In this step, we tried out various pre-processing techniques that would be best suited for Hindi language. We implemented thresholding methods such as otsu, sauvola, multiscale sauvola, wolf, etc. Among these, the best results were obtained for sauvola thresholding. Since the principle use case of this app is via the images taken from a camera, we also implemented the skew, inverse perspective transform, and deblurring that will help the tesseract to better recognise the image.
During our experiments, we observed that tesseract gives better output if the image size is smaller and the image contains only a few words and less noise. So, for every image, we build bounding blobs for words and segment the image into a definite set of boxes with single words inside them. The boxes are ordered according to rows and they are passed one by one to tesseract. The output is put together to get the entire text as a paragraph. This gives far better results as compared to tesseract for images taken on phone as such images have a lot of noise.
Post-Processing of the Tesseract output
Once we obtain the output Hindi text from Tesseract, we run a post processing step to correct the output. Specifically, we apply a prime based algorithm which finds the nearest match to a word that is not there in the Hindi dictionary. On the top of this, we have applied a Non-parametric Bayesian Language Model (Teh 2006) in order to smoothen the final output.
Translating final output to English
In this step, we use Microsoft translator to translate the Hindi text to English. We used the API of the translator in both the android as well as web application. The android application is therefore an online application.
Current Status
At present, we have both the web-application and the android application working. Below we describe these briefly.
Android Application
The android application provides the user the ability to check the output after each stage of computation. It has a very simple user interface. Users can click photos from their camera and adjust the window upon the desired hindi text that they want to translate into English. The application uses a multi-threaded architecture for fast computation of the translated text.
At present, it is not compatible with the 64-bit processors due to
initialization problem. We hope to add this in the near future. It
might also be resolved due to future updates of OpenCV Manager. The
android application can be downloaded from here.
Web Application
The web Application packs the complete workflow in a single
application. The user can provide the image either from the device or
via an url. We have built support for major image formats such as PNG,
JPEG etc., which are generated from cameras. The web application can
be accessed by visiting this link. .
A detailed project report with all the experimental details can be
accessed here.
Acknowledgements
The project is funded by Google India as part of Google - IIT Pilot
program. Saurabh Agrawal is the Google Mentor associated with the
project. The students at IITKGP, involved in the project are: Abhinav
Agarwalla (3rd year, Maths and Computing), Arna Ghosh (3rd year,
EE), Krishna Bagadia (3rd year, CSE), Shrey Garg
(3rd year, CSE) and Amrith Krishna
(Research Scholar, CSE).
|